Research highlights
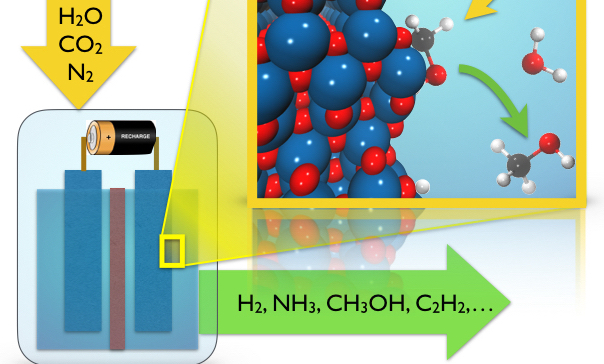
Electro-catalysis
Molecular modeling of electrochemical processes is notoriously difficult due to the complexitiy of the electrode-electrolyte interface and the non-equilibrium chemical and diffusive processes taking place under working conditions. Enhancing molecular simulation with machine learning techniques makes realistic modeling of these processes feasible.
Read further
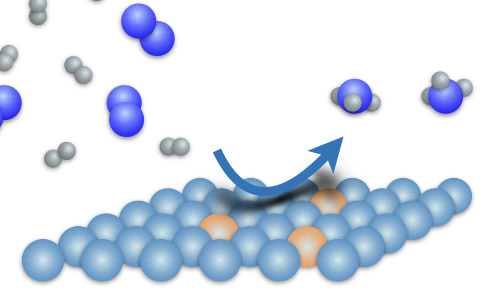
Nitrogen Fixation
We are developing a workflow for generating high-quality quantum chemical data on nitrogen-fixing coordination complexes, combining DFT calculations, MLPs and enhanced sampling to characterize their electronic and thermodynamic properties. The resulting dataset can enable the development of machine learning models for catalyst discovery without the need for exhaustive simulations of reaction pathways across diverse molecular scaffolds.
Read further
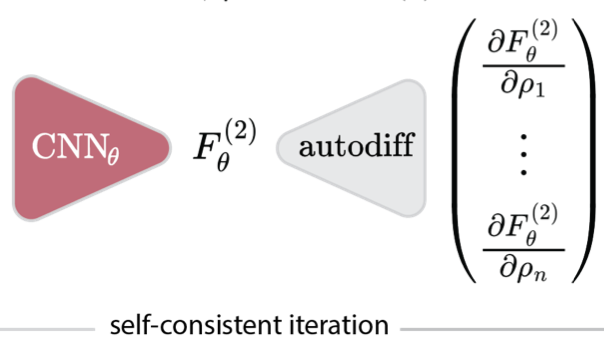
Classical DFT
We introduce a method for learning a neural-network approximation of the Helmholtz free-energy functional by exclusively training on a dataset of radial distribution functions, circumventing the need to sample costly heterogeneous density profiles in a wide variety of external potentials.
Read further